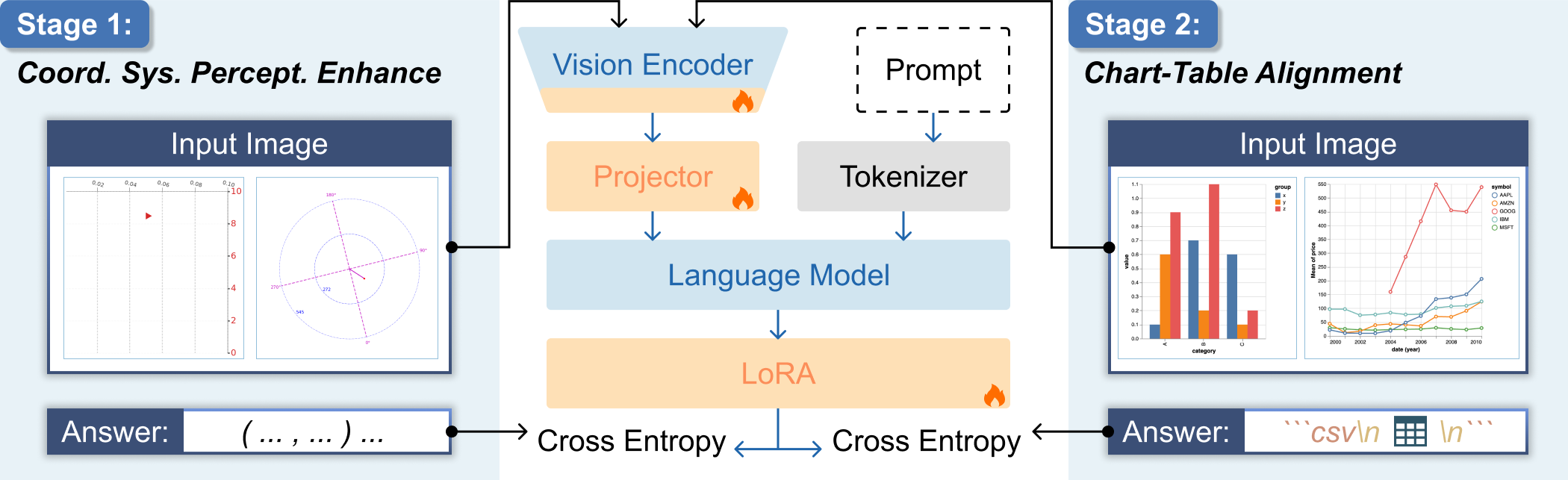
ExChart-Bench
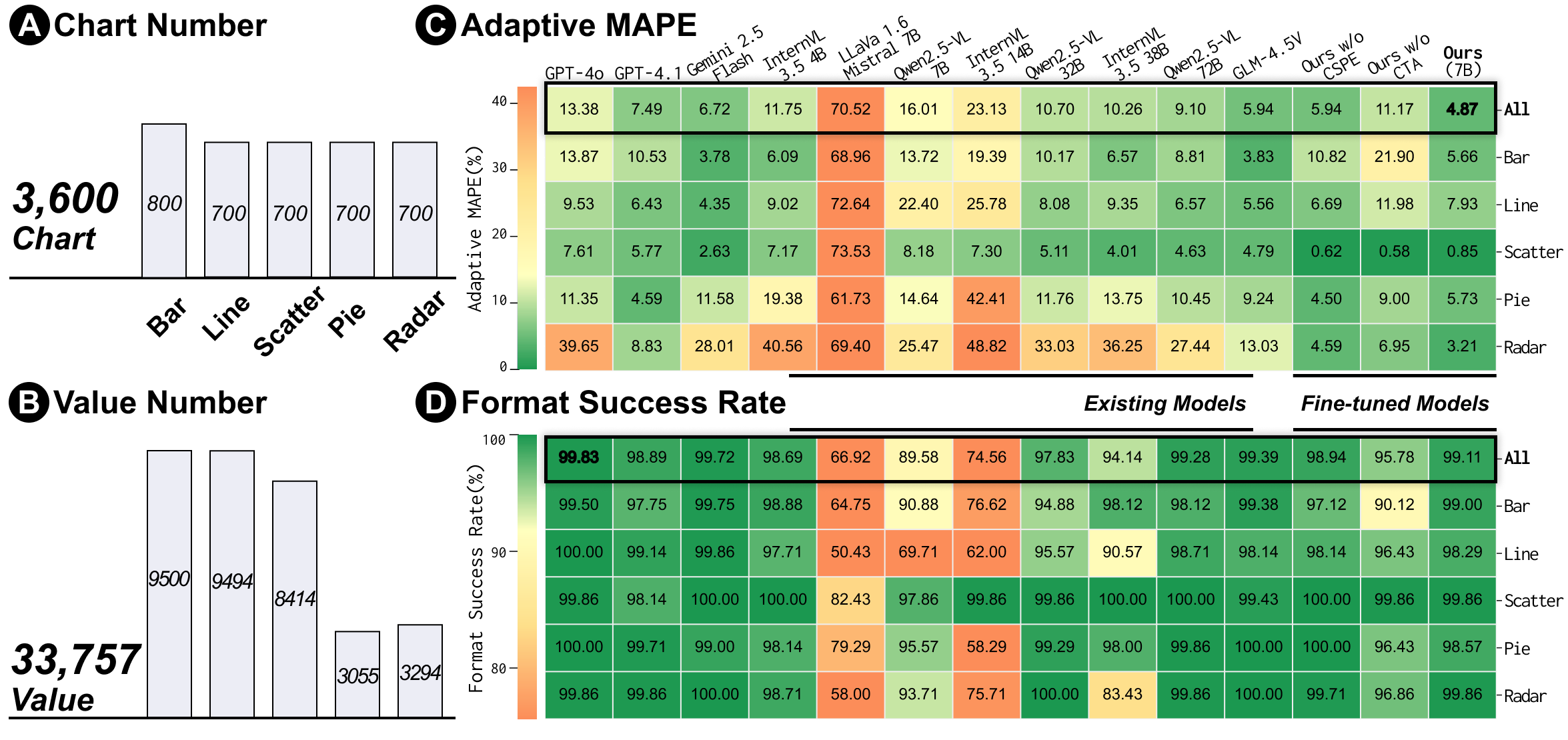
We introduce ExChart-Bench, a benchmark for evaluating MLLMs on chart data extraction.
Key Features
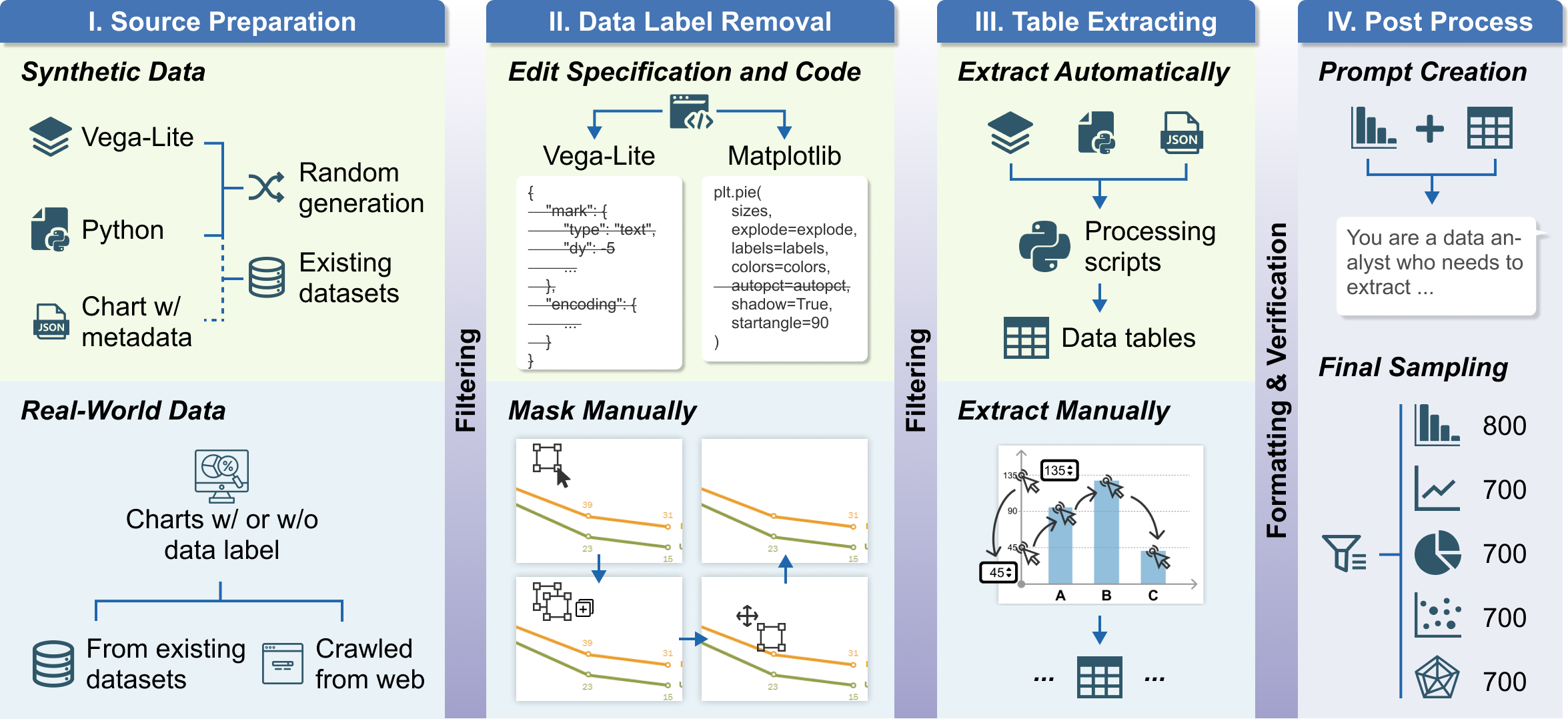
- 3,600 charts across 5 types: includes bar charts, line charts, pie charts, scatter plots, and radar charts.
- Includes real-world charts and synthetic charts
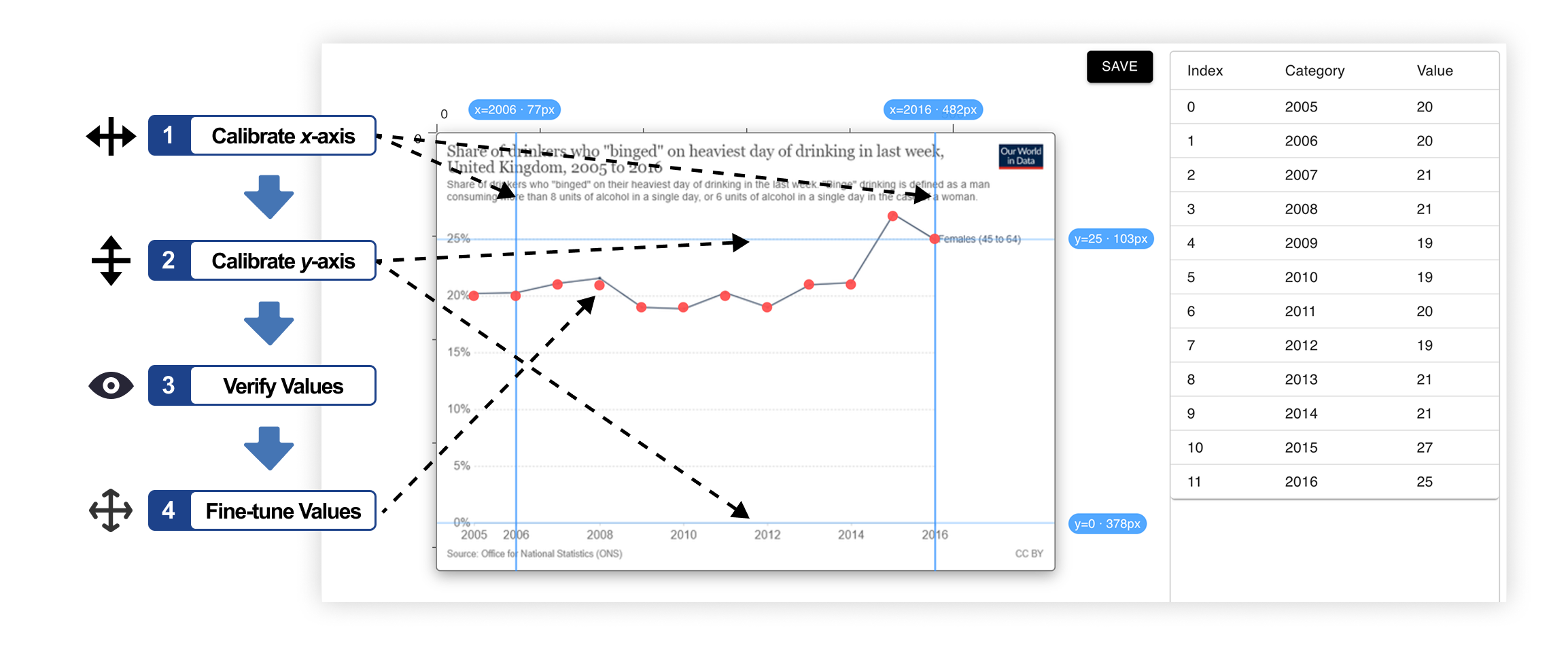
- All data labels removed: critical real-world constraint of chart data extraction.
Evaluation Results